
'谁没交作业,让我康康'
收作业不清楚谁没交,一个一个的数,太麻烦。
😏😏😏
写一个程序搞定他。
# encoding: utf-8
"""
@author: Eden
@contact: .....
@time: 2020/3/26 17:56
@file: homeWork.py
@desc: 作业查收,扫描文件夹,利用正则表达式,匹配唯一id学号
然后遍历名单,获取未交作业人员
"""
import os
import pandas as pd
import re
import threading
import zipfile
import time
def listdir(path, list_name):
"""
@param path: str
@param list_name: list
"""
for file in os.listdir(path):
file_path = os.path.join(path, file)
if os.path.isdir(file_path):
# 判断对象是否是一个目录
# 修改建议,目录直接压缩,判断压缩后的文件是否已经存在。????
listdir(file_path, list_name)
else:
# print(re.findall(r"\d+\.?\d*", file_path))
# file_path = re.findall(r"\d+\.?\d*", file_path)[0]
file_path = re.findall(r"\d+", file_path)[0] # /d匹配数字,+匹配多次
if len(file_path) != 10: # 如果学号不是10位数字,代表学号错误。
print(file_path + "是一个错误的学号")
# print(file)
# print(file_path)
list_name.add(int(file_path))
def reprint():
set_len = len(unpaid)
if set_len > 0:
print("还有%d名同学没有教作业!!" % set_len)
for index in unpaid:
print(index, df[index])
else:
print("作业已经交齐了。")
if __name__ == '__main__':
# start = time.clock()
work_path = r"E:\study\Linux高级运维\作业\Linux高级运维_shell脚本作业_第四次作业"
work_list = set()
t = threading.Thread(target=listdir, args=(work_path, work_list))
t.start()
# listdir(work_path, work_list)
excel_path = r"RenYuanMingDan.xlsx" # 人员名单
df = pd.read_excel(excel_path, encoding="utf-8", usecols=[u"姓名", u"学号"])
df = df.set_index([u"学号"])
df = df.to_dict()
df = df[u"姓名"]
t.join()
unpaid = set(df) - work_list
reprint()
# elapsed = (time.clock() - start)
# print("Time used:", elapsed)
修改版代码:
1、 解决了文件路径带有其他数字的bug。
2、目录不在进行扫描。
# encoding: utf-8
"""
@author: Eden
@contact: .....
@time: 2020/3/26 17:56
@file: homeWork.py
@desc: 作业查收,扫描文件夹,利用正则表达式,匹配唯一id学号
然后遍历名单,获取未交作业人员
"""
import os
import pandas as pd
import re
import threading
import zipfile
import time
def listdir(path, list_name):
"""
@param path: str
@param list_name: list
"""
for file in os.listdir(path):
file_path = os.path.join(path, file)
if os.path.isdir(file_path):
# 判断对象是否是一个目录
# 修改建议,目录直接压缩,判断压缩后的文件是否已经存在。????
# listdir(file_path, list_name)
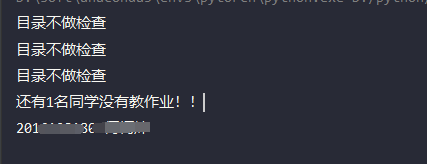
print("目录不做检查")
else:
filepath, fullflname = os.path.split(file_path)
# print(fullflname)
file_path = fullflname
try:
file_path = re.findall(r"\d+", file_path)[0] # /d匹配数字,+匹配多次
except IndexError:
print(file_path, "没有学号")
if len(file_path) != 10: # 如果学号不是10位数字,代表学号错误。
print(file_path + "是一个错误的学号,文件名 ", fullflname)
# print(file)
# print(file_path)
else:
list_name.add(int(file_path))
def reprint(unpaid):
set_len = len(unpaid)
if set_len > 0:
print("还有%d名同学没有教作业!!" % set_len)
for index in unpaid:
print(index, df[index])
else:
print("作业已经交齐了。")
if __name__ == '__main__':
# start = time.clock()
work_path = r"E:\study\大数据决策\作业\大作业"
# work_path = r"C:\Users\Eden\Desktop\笔记\自动化运维笔记"
work_list = set()
t = threading.Thread(target=listdir, args=(work_path, work_list))
t.start()
# listdir(work_path, work_list)
excel_path = r"RenYuanMingDan.xlsx" # 人员名单
df = pd.read_excel(excel_path, usecols=[u"姓名", u"学号"])
df = df.set_index([u"学号"])
df = df.to_dict()
df = df[u"姓名"]
t.join()
set_df = set(df)
# reprint(work_list)
print_set = set(df) - work_list
reprint(print_set)
# elapsed = (time.clock() - start)
# print("Time used:", elapsed)
阅读建议
评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果



